Select Parameters with Cross Validation¶
This notebook demonstrates how to select parameters of best fit for a sparse tensor decomposition model using a cross-validation strategy.
Fitting a sparse tensor decomposition model requires tuning two key parameters: the number of components (rank) of the model, and the sparsity coefficient (lambda) applied to each mode of the model. These parameters are rarely known a priori, and instead must be inferred. We’ve developed a cross-validation protocol for selecting parameters of best fit. This protocol relies on measurement replicates to generate three replicate data tensors of equivalent shapes. These replicate data tensors can be used to calculate cross-validated sum of squared error (SSE) and factor match score (FMS) metrics that can be used to identify the parameters of best fit.
We will first simulate data replicates by generating three identical simulated data tensors – rep_a, rep_b, and rep_c – with independent noise added to each tensor to simulate variation between replicates. Next we will identify the best fit number of components using cross validated SSE. Locking in this rank, we’ll fine tune the best fit sparsity coefficient using cross validated FMS.
[1]:
# imports
import numpy as np
import pandas as pd
import scipy
import seaborn as sns
import tensorly as tl
import tlviz
from barnacle import (
SparseCP,
visualize_3d_tensor,
simulated_sparse_tensor,
)
[2]:
# generate simulated data
true_rank = 5
true_shape = [20, 15, 10]
true_densities = [.2, .4, .6]
# re-seed simulated data until all factor matrices are full rank
full_rank = False
while not full_rank:
# generate simulated tensor
sim_tensor = simulated_sparse_tensor(
shape=true_shape,
rank=true_rank,
densities=true_densities,
factor_dist_list=[
scipy.stats.uniform(loc=-1, scale=2),
scipy.stats.uniform(),
scipy.stats.uniform()
],
random_state=9481
)
# check that all factors are full rank
full_rank = np.all([np.linalg.matrix_rank(factor) == true_rank for factor in sim_tensor.factors])
# create three replicates with the same core signal data tensor, and 100% independent noise added to each
rep_a = sim_tensor.to_tensor(noise_level=1, sparse_noise=True, random_state=91891)
rep_b = sim_tensor.to_tensor(noise_level=1, sparse_noise=True, random_state=7394)
rep_c = sim_tensor.to_tensor(noise_level=1, sparse_noise=True, random_state=1597)
# visualize replicates
for i, rep in enumerate([rep_a, rep_b, rep_c]):
fig = visualize_3d_tensor(
rep,
shell=False,
midpoint=0,
show_colorbar=True,
label_axes=True,
range_color=[-1, 1],
opacity=1,
)
print('Replicate {}'.format({0:'A', 1:'B', 2:'C'}[i]))
fig.show()
Replicate A
Replicate B
Replicate C
[3]:
# perform a cross-validated parameter search for the number of components (rank)
# NOTE: this block of code takes a minute or two to run
results = []
for rank in np.arange(1, 9, 1):
print(f'Fitting rank-{rank} models')
# instantiate sparse cp model
model = SparseCP(
rank=rank,
lambdas=[0, 0, 0],
nonneg_modes=[1, 2],
tol=1e-5,
random_state=21158,
n_initializations=5
)
# fit model to each replicate data tensor
for i, fit_rep in enumerate([rep_a, rep_b, rep_c]):
cp = model.fit_transform(fit_rep, verbose=0)
# calculate cross-validated SSE against each held out replicate
for j, comparison_rep in enumerate([rep_a, rep_b, rep_c]):
if i == j:
comparison = 'fitting'
else:
comparison = 'cross-validation'
sse = tlviz.model_evaluation.relative_sse(cp, comparison_rep)
results.append({
'Rank': rank,
'Fitting Replicate': {0:'A', 1:'B', 2:'C'}[i],
'Comparison Replicate': {0:'A', 1:'B', 2:'C'}[j],
'Comparison': comparison,
'SSE': sse
})
# compile results into DataFrame
rank_results_df = pd.DataFrame(results)
rank_results_df
Fitting rank-1 models
Fitting rank-2 models
Fitting rank-3 models
Fitting rank-4 models
Fitting rank-5 models
Fitting rank-6 models
Fitting rank-7 models
Fitting rank-8 models
[3]:
| Rank | Fitting Replicate | Comparison Replicate | Comparison | SSE | |
|---|---|---|---|---|---|
| 0 | 1 | A | A | fitting | 0.657666 |
| 1 | 1 | A | B | cross-validation | 0.707090 |
| 2 | 1 | A | C | cross-validation | 0.714235 |
| 3 | 1 | B | A | cross-validation | 0.674137 |
| 4 | 1 | B | B | fitting | 0.691348 |
| ... | ... | ... | ... | ... | ... |
| 67 | 8 | B | B | fitting | 0.352665 |
| 68 | 8 | B | C | cross-validation | 0.648890 |
| 69 | 8 | C | A | cross-validation | 0.645520 |
| 70 | 8 | C | B | cross-validation | 0.646472 |
| 71 | 8 | C | C | fitting | 0.341968 |
72 rows × 5 columns
[4]:
# identify the rank of best fit
# find the rank that corresponds to the minimum mean cross-validated SSE
cv_sse_df = rank_results_df[rank_results_df.Comparison == 'cross-validation'].groupby('Rank').mean('SSE')
minimum = cv_sse_df.reset_index().sort_values('SSE').iloc[0, :]
print(f'The minimum cross-validated SSE ({minimum.SSE:.2f}) corresponds to a rank of {int(minimum.Rank)}.')
# visualize cross-validation data
ax = sns.lineplot(
rank_results_df,
x='Rank',
y='SSE',
hue='Comparison',
errorbar='se',
err_style='bars'
)
The minimum cross-validated SSE (0.56) corresponds to a rank of 5.
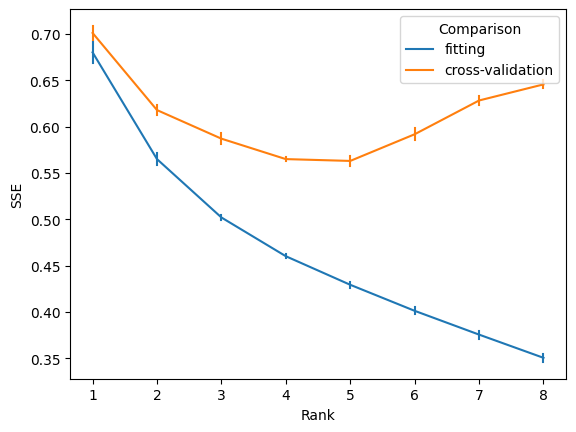
The cross-validation result reveal a clear minimum in cross-validated SSE that corresponds to a rank of 5. This indicates that the model of best fit should be parameterized with 5 components. However, this parameterization was done in the absence of any sparsity parameter (lambda=0). So fixing the number of components at 5, we next perform a similar cross-validated parameter search of sparsity coefficients to identify the ideal sparsity level for the model.
[5]:
# perform a cross-validated parameter search for the sparsity coefficient
# NOTE: this block of code takes a minute or two to run
# define range of lambda values to test
lambdas = [0.05, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.8, 1.]
results = []
for lamb in lambdas:
print(f'Fitting models with sparsity coefficient of {lamb}')
# instantiate sparse cp model
model = SparseCP(
rank=5,
lambdas=[lamb, 0, 0],
nonneg_modes=[1, 2],
tol=1e-5,
random_state=21158,
n_initializations=5
)
# fit model to each replicate data tensor
fit_models = []
for i, fit_rep in enumerate([rep_a, rep_b, rep_c]):
cp = model.fit_transform(fit_rep, verbose=0)
fit_models.append(cp)
# calculate cross-validated FMS and SSE between each pair of replicates
for i, fit_rep in enumerate([rep_a, rep_b, rep_c]):
for j, comparison_rep in enumerate([rep_a, rep_b, rep_c]):
if i == j:
continue # only compute cross-validated metrics
elif i < j:
fms = tlviz.factor_tools.factor_match_score(fit_models[i], fit_models[j])
else:
fms = np.nan # FMS is symmetrical, so FMS(A, B) == FMS(B, A)
sse = tlviz.model_evaluation.relative_sse(fit_models[i], comparison_rep)
results.append({
'Sparsity Coefficient': lamb,
'Fitting Replicate': {0:'A', 1:'B', 2:'C'}[i],
'Comparison Replicate': {0:'A', 1:'B', 2:'C'}[j],
'SSE': sse,
'FMS': fms
})
# compile results into DataFrame
lambda_results_df = pd.DataFrame(results)
lambda_results_df
Fitting models with sparsity coefficient of 0.05
Fitting models with sparsity coefficient of 0.1
Fitting models with sparsity coefficient of 0.2
Fitting models with sparsity coefficient of 0.3
Fitting models with sparsity coefficient of 0.4
Fitting models with sparsity coefficient of 0.5
Fitting models with sparsity coefficient of 0.6
Fitting models with sparsity coefficient of 0.8
Fitting models with sparsity coefficient of 1.0
[5]:
| Sparsity Coefficient | Fitting Replicate | Comparison Replicate | SSE | FMS | |
|---|---|---|---|---|---|
| 0 | 0.05 | A | B | 0.563678 | 0.621984 |
| 1 | 0.05 | A | C | 0.575991 | 0.587359 |
| 2 | 0.05 | B | A | 0.573267 | NaN |
| 3 | 0.05 | B | C | 0.561255 | 0.665616 |
| 4 | 0.05 | C | A | 0.549828 | NaN |
| 5 | 0.05 | C | B | 0.543003 | NaN |
| 6 | 0.10 | A | B | 0.569468 | 0.621996 |
| 7 | 0.10 | A | C | 0.563350 | 0.559078 |
| 8 | 0.10 | B | A | 0.553518 | NaN |
| 9 | 0.10 | B | C | 0.568633 | 0.580420 |
| 10 | 0.10 | C | A | 0.546041 | NaN |
| 11 | 0.10 | C | B | 0.538591 | NaN |
| 12 | 0.20 | A | B | 0.565581 | 0.601660 |
| 13 | 0.20 | A | C | 0.558382 | 0.559783 |
| 14 | 0.20 | B | A | 0.542834 | NaN |
| 15 | 0.20 | B | C | 0.533984 | 0.773011 |
| 16 | 0.20 | C | A | 0.544073 | NaN |
| 17 | 0.20 | C | B | 0.534930 | NaN |
| 18 | 0.30 | A | B | 0.564586 | 0.603628 |
| 19 | 0.30 | A | C | 0.558994 | 0.558960 |
| 20 | 0.30 | B | A | 0.540832 | NaN |
| 21 | 0.30 | B | C | 0.532331 | 0.783579 |
| 22 | 0.30 | C | A | 0.544599 | NaN |
| 23 | 0.30 | C | B | 0.534873 | NaN |
| 24 | 0.40 | A | B | 0.567422 | 0.601039 |
| 25 | 0.40 | A | C | 0.562392 | 0.555470 |
| 26 | 0.40 | B | A | 0.541534 | NaN |
| 27 | 0.40 | B | C | 0.533658 | 0.789679 |
| 28 | 0.40 | C | A | 0.548292 | NaN |
| 29 | 0.40 | C | B | 0.537406 | NaN |
| 30 | 0.50 | A | B | 0.571722 | 0.590569 |
| 31 | 0.50 | A | C | 0.567495 | 0.550812 |
| 32 | 0.50 | B | A | 0.549326 | NaN |
| 33 | 0.50 | B | C | 0.565389 | 0.619288 |
| 34 | 0.50 | C | A | 0.554570 | NaN |
| 35 | 0.50 | C | B | 0.542781 | NaN |
| 36 | 0.60 | A | B | 0.577466 | 0.577193 |
| 37 | 0.60 | A | C | 0.574194 | 0.542921 |
| 38 | 0.60 | B | A | 0.555087 | NaN |
| 39 | 0.60 | B | C | 0.570769 | 0.620740 |
| 40 | 0.60 | C | A | 0.561618 | NaN |
| 41 | 0.60 | C | B | 0.549689 | NaN |
| 42 | 0.80 | A | B | 0.594029 | 0.437480 |
| 43 | 0.80 | A | C | 0.592781 | 0.523104 |
| 44 | 0.80 | B | A | 0.606608 | NaN |
| 45 | 0.80 | B | C | 0.617170 | 0.465549 |
| 46 | 0.80 | C | A | 0.577298 | NaN |
| 47 | 0.80 | C | B | 0.566667 | NaN |
| 48 | 1.00 | A | B | 0.635231 | 0.313387 |
| 49 | 1.00 | A | C | 0.636494 | 0.521444 |
| 50 | 1.00 | B | A | 0.627666 | NaN |
| 51 | 1.00 | B | C | 0.639601 | 0.454012 |
| 52 | 1.00 | C | A | 0.597917 | NaN |
| 53 | 1.00 | C | B | 0.590343 | NaN |
[6]:
# identify the sparsity coefficient of best fit
# find the lambda that corresponds to the minimum mean cross-validated SSE
cv_df = lambda_results_df.groupby('Sparsity Coefficient').mean(['SSE', 'FMS']).reset_index()
min_sse = cv_df.sort_values('SSE').iloc[0, :]
print(f"The minimum cross-validated SSE ({min_sse.SSE:.2f}) " +
f"corresponds to a sparsity coefficient of {min_sse['Sparsity Coefficient']}.")
# find the lambda that corresponds to the maximum mean cross-validated FMS
cv_df = lambda_results_df.groupby('Sparsity Coefficient').mean(['SSE', 'FMS']).reset_index()
max_fms = cv_df.sort_values('FMS', ascending=False).iloc[0, :]
print(f"The maximum cross-validated FMS ({max_fms.FMS:.2f}) " +
f"corresponds to a sparsity coefficient of {max_fms['Sparsity Coefficient']}.")
# arrange data in tidy format for plotting
plot_df = lambda_results_df.melt(
id_vars=['Sparsity Coefficient', 'Fitting Replicate', 'Comparison Replicate'],
value_vars=['SSE', 'FMS'],
var_name='Metric',
value_name='Score'
)
# visualize cross-validation data
ax = sns.lineplot(
plot_df,
x='Sparsity Coefficient',
y='Score',
hue='Metric',
errorbar='se',
err_style='bars'
)
ax.set(xscale='log');
The minimum cross-validated SSE (0.55) corresponds to a sparsity coefficient of 0.3.
The maximum cross-validated FMS (0.65) corresponds to a sparsity coefficient of 0.4.
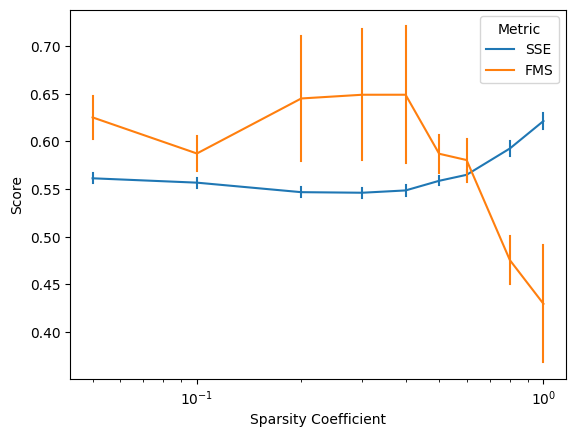
Evidenced by these results, selecting the best sparsity coefficient is not always a straightforward task. However, in this example it is reassuring to see that the cross-validated SSE and FMS scores point to a similar range of sparsity coefficient values between 0.2 and 0.4. Above this range, there is a clear drop off in FMS and an increase in SSE, and below this range there is a similar trend that is subtler but nevertheless distinct.
Within the indicated range, selecting the most appropriate sparsity coefficient probably depends on the intended application of the model. There are a number of hueristics that can help, such as the “one standard error rule” in which we select the sparsest model for which the cross-validated score remains within one standard error of the best overall score. In this example, this heuristic might lead to a selection of 0.4 as the sparsest model of best fit.